


Jane Street’s intern program yet again is coming to an end, which is a nice opportunity to look back over the summer and see what they’ve accomplished.
Between our 54 interns in New York, London, and Hong Kong (who came from 32 schools in 13 countries!), there’s far too many projects to recount here. So, instead of doing an overview, I’ll just a pick a few different projects to highlight the breadth of work that was done.
The first project I’ll discuss is latviz, a plotting tool for visualizing latencies; the second is vcaml, a layer for extending Neovim in OCaml. And the third is about implementing an LDAP library.
Visualizing latencies
Lots of what happens in a trading infrastructure is the shipping around of data, really, a disturbing amount of data. Much of that data is marketdata from various exchanges, and a lot of it is data that’s generated internally, often in response to marketdata updates.
For these systems to work well, they need to distribute messages with low and deterministic latency. As a result, we spend a lot of time and effort trying to measure, analyze, and understand our latencies. We tend to do this by leveraging specialized hardware devices to capture and timestamp network traffic, and then do a bunch of post-hoc analysis to actually see what the latencies are.
And then, after we’ve done all that work, we tend to visualize this data by generating ascii-formatted tables containing summaries of the latencies.
Sigh.
While I love old-school, text-based UIs, they’re sometimes just a poor fit. Well-designed, interactive visualizations can do a lot to make it easier for people to quickly and easily understand what the data is trying to tell them.
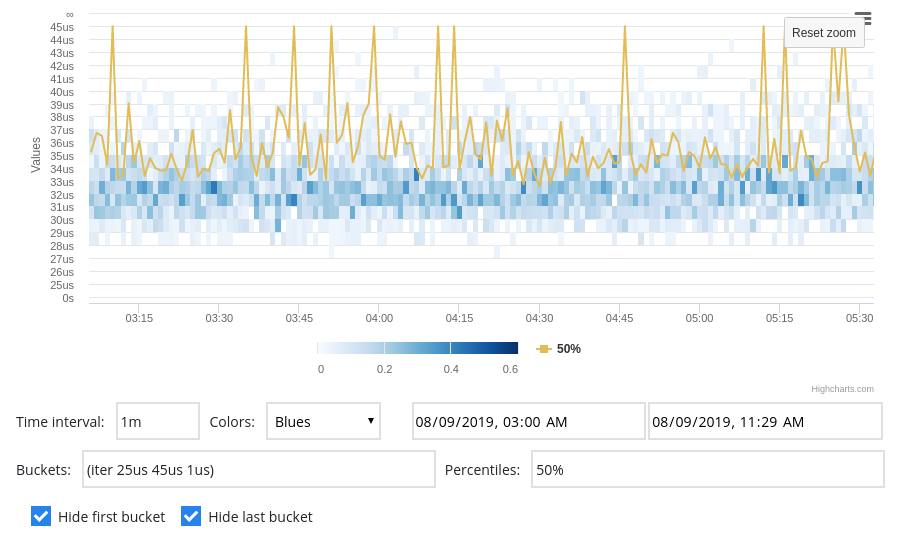
Lukasz Miskiewicz’s project (mentored by Maciej Debski) was to create just such a tool for visualizing latency data, called latviz. Because latency problems are often related to issues that are localized in time, like data rate spikes, or network configuration issues, it’s often useful to be able to see how latencies vary over the day. One of the goals of latviz was to make the time-dependent nature of latency data easy to see, unlike our ordinary ways of presenting the data.
Here’s what the final result looks like.
The project had a few different parts.
-
A high-level and type-safe wrapper over Highcharts, a widely used JavaScript graphing library. We write our web applications in OCaml, which allowed Lukasz to use some more advanced features of the OCaml type system (specifically, GADTs) to make the API less error-prone.
-
The latviz webclient, based on the aforementioned Highcharts library and the Incr_dom framework.
-
A back-end which allows us to efficiently compute the statistics required to generate the visualization. This was based on a commercial column-oriented database, and required some cleverness around the construction of the tables and the queries to make it all run acceptably fast.
-
A tool for loading latency data into the system. One of the difficulties here is that our latency data is based on network captures, which means there’s a ton of data to rip through. Accordingly, Lukasz built a tool that could efficiently down-sample the data, using reservoir sampling, and send the resulting data to the latviz server.
All told, we’re excited about the results. It makes it easier to see what’s going on, and the tool is efficient enough that you can tweak the way in which the data is put together (for example, changing the percentiles that are plotted, or the size and distribution of buckets in the historgram), and get back an updated visualization almost immediately.
Right now the tool has only been applied to a single system, but it’s already helped us find one real performance regression, and we hope that over the coming months we hope to make latviz available more broadly.
Automating Vim
We care a lot about dev-tools. Developer time is precious, and great tools make developers more efficient, not to mention happier.
And there are lots of different pieces of infrastructure we work on to improve developers’ lives: the OCaml compiler, documentation generators, continuous-integration systems, code review tools, testing frameworks, and so on. But if I had to pick one tool that is most intertwined with developers’ daily lives and about which they have the strongest feelings, I think it would have to be their editor.
Accordingly, we’ve spent a lot of time over the years improving the editor experience here, and doing a lot of work to integrate our various dev-tools seamlessly into the editor. This was highlighted by this post on Feature Explorer, which is our integration of Iron, our code review system, into Emacs.
And, there’s the rub: most of this integration work has been done in Emacs. Emacs is the editor that we recommend to new hires, and I once hoped that we’d eventually make the Emacs experience good enough that people wouldn’t clamor for us to support anything else.
That was a vain hope. Vim users are a stubborn and resourceful bunch, and we’ve always had a solid minority of developers who use Vim, mostly figuring out their own customizations and integrations to make it nicer to use Vim in our environment.
Recently, our tools group has decided to start taking on more responsibility for Vim tooling. And the first step there is to make it easier to create tooling for Vim. Currently, if you want to customize Vim, you need to write vimscript, a programming language that I’ve never heard anyone speak kindly about.
On the Emacs side, we dealt with a similar problem, in that elisp, while not nearly as bad of a language as vimscript, is not a great tool for writing and maintaining complex extensions. That’s why we created ecaml, a set of libraries that target Emacs’ FFI so you can write your extensions entirely in OCaml. (Amusingly, the first version of ecaml was also an intern project, done by Aaron Zeng, now a full-timer!) Today, essentially all of our Emacs extensions are written in OCaml.
This summer, intern Cameron Wong (mentored by Ty Overby) worked on adding the equivalent functionality for Vim (or really, Neovim), in the form of a library called vcaml.
The reason they chose Neovim rather than Vim is that the former has an asynchronous RPC based mechanism (built on MessagePack) that lets you control the editor at a fairly low level. We wanted to write high-level OCaml bindings to this, so the first step was to dump all of the APIs and their types.
From this, Cameron generated low-level (and somewhat type-safe) bindings for all the APIs, after first using the Angstrom and Faraday libraries for building parsers and printers for MessagePack. The implementations of these APIs wind up serializing all of the arguments into a MessagePack list, and getting back a MessagePack object to deserialize.
There is a fly in this ointment, though. Because this is an RPC-based
mechanism, you can end up in various race conditions when a sequence
of operations that you want to happen atomically get interrupted.
Happily, Neovim has a workaround for this; a call_atomic function,
which takes the arguments for multiple functions and calls them all
in sequence without allowing anything else to interrupt.
This leaves you, unfortunately with a somewhat awkward API design question, in that it’s not totally clear how to build an easy-to-use, strongly typed interface that lets you combine together multiple RPC calls into one, while still giving easy access to the results of the constituent calls.
The solution, it turns out, was to turn this into an
Applicative.
The applicative interface, along with the
ppx_let syntax extension,
provides an easy-to-use and type-safe interface for constructing such
calls.
For a somewhat artificial example, let’s say we want to build an API
call that atomically gets out the first and last lines out of a
buffer. The Buf.get_lines call will let us query lines from
anywhere in the buffer, and we can the applicative let-syntax for
joining those together into a single call that atomically grabs both
values.
let get_first_and_last buffer =
let open Api_call.Let_syntax in
let%map first = Buf.get_lines ~buffer ~start:0 ~end_:1 ~strict_indexing:true
and last = Buf.get_lines ~buffer ~start:(-1) ~end_:0 ~strict_indexing:true in
first, last
;;
It’s still early days, but we’re excited about the potential this has to improve our tooling around Vim. And our plan is to release all of this as open source in the coming months.
Reimplementing LDAP
If you just know about Jane Street from our tech blog, you might think we do everything on Linux, but that’s far from the case. While most of our home-grown software runs on Linux, we have a big Windows infrastructure, mostly oriented towards supporting our Windows desktop machines.
Part of supporting that infrastructure is interfacing with Active Directory, and in particular, having the ability to communicate to the DCs (Domain Controllers); and ideally, we want to be able to do so from our ordinary OCaml codebase.
And indeed, we’ve long had a solution for doing so. DCs speak an open protocol called LDAP (short for Lightweight Directory Access Protocol), and for the last 8 years, we’ve used Ocamldap, an open-source OCaml library, for speaking LDAP to the DCs.
Ocamldap has been enormously useful, but there are some problems with it as well.
- It makes heavy use of Unix alarms instead of using Async, which makes it hard to integrate into our programs, often leaving us with weird crashes and segfaults.
- It implements a bunch of basic services on its own, like SSL, in its own custom way. That was necessary when Ocamldap was written, but today, there are a bunch of new libraries for doing this kind of stuff that works better than the custom implementations in Ocamldap.
- The basic design is exception-heavy, which leads to surprising and sometimes uninformative messages when things go wrong.
- It’s not actively developed. It’s been responsibly maintained over the years, but there’s not a lot of serious new development at this point.
The project we gave to intern Xueyuan Zhao (mentored by Nolen Royalty) was to build a new LDAP implementation to replace ocamldap.
There were a bunch of parts that went into the project. LDAP makes use of ASN.1 and is encoded using BER. Happily, the spec is reasonably straightforward. The mirage folks have a great asn1 library already, so the first step was creating types to represent the primitives described in the RFC using their combinators. One tricky thing here is that search filters are recursive.
In OCaml, you could write a recursive type for a simple filter language like this:
module Search_filter
type t =
| And of t list
| Or of t list
| Equals of string
end
In the ASN.1 library, recursion is a little less straightforward. In
particular, this requires use of the fixpoint combinator to allow us
to construct a parser that refers to itself, as shown below.
let asn =
fix
@@ fun asn ->
choice10
(* and *)
(implicit 0 (set_of asn))
(* or *)
(implicit 1 (set_of asn))
(* not *)
(explicit 2 asn)
(* equaliltyMatch *)
(implicit 3 Attribute_value_assertion.asn)
(* substrings *)
(implicit 4 Substring_filter.asn)
(* greaterOrEqual *)
(implicit 5 Attribute_value_assertion.asn)
(* lessOrEqual *)
(implicit 6 Attribute_value_assertion.asn)
(* present *)
(implicit 7 Attribute_description.asn)
(* approxMatch *)
(implicit 8 Attribute_value_assertion.asn)
(* extensibleMatch *)
(implicit 9 Matching_rule_assertion.asn)
;;
Once we came up with a way to encode and decode LDAP we needed to convince ourselves that we were doing the right thing. We tested our new encodings by writing expect tests that encoded the same queries using ocamldap and our new jane-ldap library, and diffed the results.
In some cases the encoding that we ended up with was different. Debugging that was really fun: we’d end up with a test that looked like this:
let%expect_test _ =
let ours = Ldap.Protocol.encode_message msg in
let theirs = Ocamldap.Ldap_protocol.encode_ldapmessage msg in
print_endline (hex_of_string ours);
print_endline (hex_of_string theirs);
[%expect
{|
30 16 02 01 01 61 11 0a 01 00 04 00 04 00 a3 06 04 01 41 04 01 42 87 00
30 16 02 01 01 61 11 0a 01 00 04 00 04 00 a3 06 04 01 41 04 01 42 04 00 |}]
And then reverse engineer what the second-to-last byte of the message contained, what we were encoding, and what ocamldap was encoding. In some cases we found bugs in our code, but in some cases we found bugs in ocamldap.
The final bit of the project, which isn’t quite complete, is to wrap up our now-functional parser in a nice client library that doesn’t require users to read the whole LDAP RFC. While some Jane Street libraries like async_ssl get you some basic plumbing for free, one of our goals was to produce a native Async library (instead of a library that was only async via In_thread.run and some hope), which means that the library needs to have the ability to track, encode, and decode many different queries/responses concurrently. The LDAP protocol provides the basic tooling to do this - each query is uniquely identified by a ‘message id’ - but it adds some extra complexity and state.
All told, we’re excited about the prospects of this work, and hope to get the results open sourced.
You could be an intern too!
I hope the above project descriptions have given you a sense of the scope and diversity of projects interns get to work on. Jane Street interns get to do real, and really interesting, development work.
So, if this sounds like fun, you should apply! Jane Street internships are a great learning experience, and a lot of fun. And if you’re interested in learning more about the application process, this is a pretty good place to start.
(Links to Reddit and HN, if you want to comment on the post.)



