

Updates and a New Run
First, some brief updates:
Earlier this year, I posted about our project KataGo and research to improve self-play learning in Go, with an initial one-week run showing highly promising results.
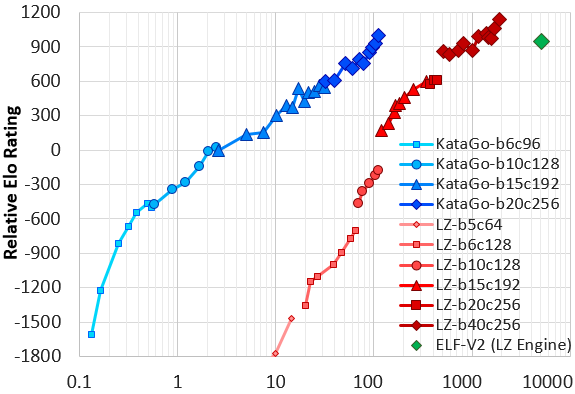
Several months later in June, KataGo performed a second, longer 19-day run with some major bugfixes and minor optimizations. Starting from scratch and with slightly less hardware than before, up to 28 V100 GPUs, it reached and surpassed the earlier one-week run in barely more than the first three days. By the end of the 19 days, it had reached the strength of ELF OpenGo, Facebook AI Research’s multi-thousand-GPU replication of one of AlphaZero’s runs - equating to roughly a factor of 50 reduction in computation required. Our paper has since been significantly revised and updated with the new results:
Accelerating Self-Play Learning in Go (arxiv paper)
This version of KataGo has also been released to the Go player community for several months now. With the results of this second run, KataGo is comparable to other top-level open-source bots and is now one of the more popular bots online for its ability to play handicap games - to come up with strong moves even starting at a great disadvantage by secondarily optimizing for score, something that ELF and other “AlphaZero”-trained bots fail to do well [1]. KataGo is also popular for game analysis using some of the more major analysis GUIs also due to its ability to estimate the score, ownership, and to adjust to alternate board sizes and rules.
The Hardest Go Problem in the World?
Along the way, development and research in KataGo has spawned for us many new questions and side-branches to explore. One of these questions revolved around a challenge: understanding the “hardest” Go problem in the world.
Igo Hatsuyoron is a classic problem collection dating back to 1713, compiled and much of it likely composed by Inoue Dosetsu Inseki, the head of the Inoue house of Go and holding the title of Meijin, the strongest recognized player in Japan. Igo Hatsuyoron is still widely-recognized today as one of the most difficult and high-caliber Go problem collections in existence.
In particular, the 120th problem in the collection is often considered to be the deepest and hardest Go problem ever composed. Its main line features a counterintuitive “hanezeki” formation, and buried within its depths are many variations involving enormous trades, knife-edge races between huge groups balanced with no margin for error, and subtle early choices that have effects as much as 100 moves later. Despite many total person-years of study and even a few published books devoted to analyzing the problem (for example: here at amazon.cn), the problem is still considered unsolved, with many classical solutions seemingly refuted and modern lines still not entirely certain.

As far as we are aware, all prior bots including those developed since AlphaZero, almost completely fail to understand this problem. The highly unusual shapes cause them to completely miss many of the key moves and ideas, and the incredible precision of the fights prevents the generic knowledge that they have learned from being effective, the June version of KataGo included. In fact, even in ordinary games, long-distance/large-scale fights and blind spots of specific unusual shapes are known weaknesses of current otherwise superhuman bots[2], and sometimes humans can outdo them in those situations - and this problem hits both such weaknesses hard.
Could a bot be trained to understand this problem?
Normally, training consists of self-playing hundreds of thousands of ordinary games. We learned from AlphaZero that this makes the bot very, very good at ordinary games.
So what if self-play consisted instead of exploration of this specific problem? Would the bot then master this problem?
It seemed possible or even likely, but it seems nobody had tried it yet. So I contacted Thomas Redecker, one of the authors of a website containing an excellent modern analysis of the problem and who had earlier publicized some of the ways that modern bots uniformly all fail, and began training KataGo specifically on it.
Training Summary
- In total, KataGo trained for 1 week on this problem on the same 28 GPUs as before, beginning from the strongest neural net from the end of its second run, around the full strength of ELF OpenGo.
- Training used much the same self-play process as the earlier June run did, including all the same learning enhancements[3] and the full learning rate used during most of the June run. The primary difference was that rather than only starting games from the initial empty board, games were also started from Igo Hatsuyoron 120.
- About 70% of self-play games started from positions in Igo Hatsuyoron 120. 30% were kept as as ordinary games to regularize and to keep KataGo effective at ordinary games.[4]
- Among the 70%, we started about 1/6 from the initial position of Igo Hatsuyoron 120, and started about 5/6 from random positions from subvariations from prior human solutions and some of the bot’s own preferred lines in the first few days of training.
- Starting from subvariations was because we specifically wanted KataGo to be able to analyze numerous prior human solution attempts, and also were not sure initially whether a bot could learn the problem well at all (large-scale-fight-perception and unusual-shape-blind-spots being precisely two of the weaknesses of modern bots).
- Random starting positions were chosen with probability exponentially decreasing in turn number such that each turn number was roughly equally likely. This is because uniform weighting would overwhelmingly weight positions at the very end of the game with almost nothing left to play, since the number of variations branches exponentially.
- KataGo was not informed of the human-believed best move or evaluation in any position - positions were purely used only as the initial board state for self-play games.
- Since the goal of the problem is to find the score-optimal result, not merely to win, we variably set komi in any starting position to the value that KataGo believed at that time would be fair, making score-precise play also necessary for winning/losing. (Plus mild additional normally-distributed noise, sigma = 1 point, for regularization).
- We approximately cut in half the lookback window from the end of the June run for sampling training data for gradient updates, to reduce the amount of time for new Igo Hatsuyoron 120 data to fill the window and to reduce the overall latency of the learning loop for adapting to the new data.
Overall, the training process was somewhat informal and exploratory, being tacked on to the end of an existing strong regular run and borrowing many of its hyperparameters without further consideration. Repeating it with more careful setting of hyperparameters and with additional runs would be useful to get a better controlled comparison of methods - our goal here was just to see how well this would work at all.
Results
The progress of training was fun to watch. From limited anecdotal observation of KataGo’s preferred lines during training, KataGo was constantly re-discovering and changing its mind between many known human variations at different points. It seemed much of the week of training was “necessary”, with KataGo re-discovering the “guzumi” move - one of the strangest moves found earlier by humans and believed to be part of the main line - only in the last few days.

As far as we can tell, KataGo now displays an overall strong understanding of the elements of this problem and displays a sensitivity to even single-liberty differences in the major fights. It confirms most of the surprising tactics found earlier by humans, and also finds what appears to be a small number of apparent mistakes and/or simpler refutations in some side variations of human analyses.
And excitingly, it also suggests a few new moves along the main line! Whereas the tentative best known human line led to a win by 3 points for Black, as a result of these new moves, KataGo seems to believe that White will win by 2 points, or at least by 1 point.[5]

Do these moves work and is this solution correct? Some human study of these moves has already been started and seems to support their soundness, but it is not entirely clear yet. And of course, given the vast depth of the problem, it’s hard to rule out further training or future research uncovering other moves elsewhere. KataGo’s own understanding also does not appear to be perfect. In a few lines, it gives overconfident or underconfident estimates with large error relative to deeper evaluations from playing out the line, and in some lines it can require significant numbers of playouts (at least tens of thousands) before it reliably settles on what seem to be the right moves. However, at a minimum KataGo is now at the point of being a powerful analysis aid for this problem and is the first bot to have a good understanding of it.
KataGo’s tentative main line can be viewed here:
Future Work
Our training run here was fairly informal and exploratory, and leaves many open questions still:
-
How reliably would the results replicate in repeated and more carefully-controlled training runs?
-
How well would a bot do if trained only from the starting position of Igo Hatsuyoron 120 - would it explore enough to avoid getting stuck, and how much slower would it converge?
-
Is there a cheaper way to make a bot good at “constructed” problems than to run full-scale self-play-training on the problems individually?
-
Due to problem-specific-training, KataGo seems to have dodged large-scale-fight weaknesses and unusual-shape weaknesses common to Zero-trained bots for specific problem, but is there a more general way to remedy those issues?
-
And of course, for Go players - are there still more surprises or new moves left to be discovered in this beautifully well-balanced and deep problem?
The final trained neural net is available here for anyone to use with KataGo to explore and analyze on their own.[6]
For anyone else who might also be interested in trying an independent replication or otherwise to experiment with such methods, we hope these are some fun and interesting questions that can be explored in the future!
Acknowledgements
Many thanks to Michael Redmond (professional 9 dan) for consultation and preliminary analysis of KataGo’s variations, and to Thomas Redecker, Harry Fearnley, and Joachim Meinhardt for collaboration and consultation on this project.
Endnotes
[1]: When well behind and every move seems almost 100% losing, without a secondary signal such as score, AlphaZero-style bots lose any idea of how to play and begin to behave extremely poorly.
[2]: We suspect large-scale-fight perception and blind-spot weaknesses in Go are related to more general issues in modern deep reinforcement learning regarding the robustness of learned models and insufficient exploration of certain strategies. Although Go bots are still superhuman on average, such failings seem to be echoes of the same kinds of issues encountered by AlphaStar and Open AI Five that prevented them from achieving clearly superhuman levels.
[3]: One significant additional modification not part of the June run was used as well, which was to overweight the frequency of positions with high policy KL-divergence (essentially, high policy loss) in the training data. Some time after the June run but before this project, we’d separately found this to be a mild improvement for training, and hope to incorporate it more generally in a third major run in the next few months.
[4]: Actually, the ratio used was 50-50 initially, but it was raised shortly after starting based on some intuition that more focused training would be good and from noticing that Igo Hatsuyoron games would be underweighted as a proportion of the data at 50-50 since they last for many fewer moves than normal games due to the board already being partly filled up.
[5]: There is some uncertainty about the final difference due to the fact that like all “AlphaZero”-based bots to-date, KataGo does not yet natively support Japanese rules, due to difficulties in formalizing that ruleset for self-play (and Igo Hatsuyoron is a Japanese-composed problem). Due to a parity difference in how the score is defined, the Japanese rules disagree with more computer-friendly “area” or “Chinese” rulesets by 1 point a nontrivial fraction of the time.
[6]: For anyone who does find anything, a good venue for discussion might be the Life in 19x19 forums such as in this thread here - note: these forums are in NO way affiliated with Jane Street, they are external discussion forums about Go.



