

At Jane Street, over the last few years, we’ve been increasingly exploring machine learning to improve our models. Many of us are fascinated by the rapid improvement we see in a wide variety of applications due to developments in deep learning and reinforcement learning, both for its exciting potential for our own problems, and also on a personal level of pure interest and curiosity outside of work.
About a year ago, motivated by AlphaGo and AlphaZero, I started a personal research project outside of work to experiment with neural net training in Go. While there was plenty to experiment with in just supervised learning and search alone, it wasn’t too long before I accumulated a variety of ideas that would each take at least part of an actual self-play training run to properly test. This was tricky, since self-play training in a game as large as Go requires a very large amount of compute. A single full run by AlphaZero required thousands of TPUs over several days, Facebook’s ELF OpenGo used two thousand GPUs for more than a week, and Leela Zero, an distributed open-source project running off of computation donated by volunteers has taken more than a year to reach top levels.
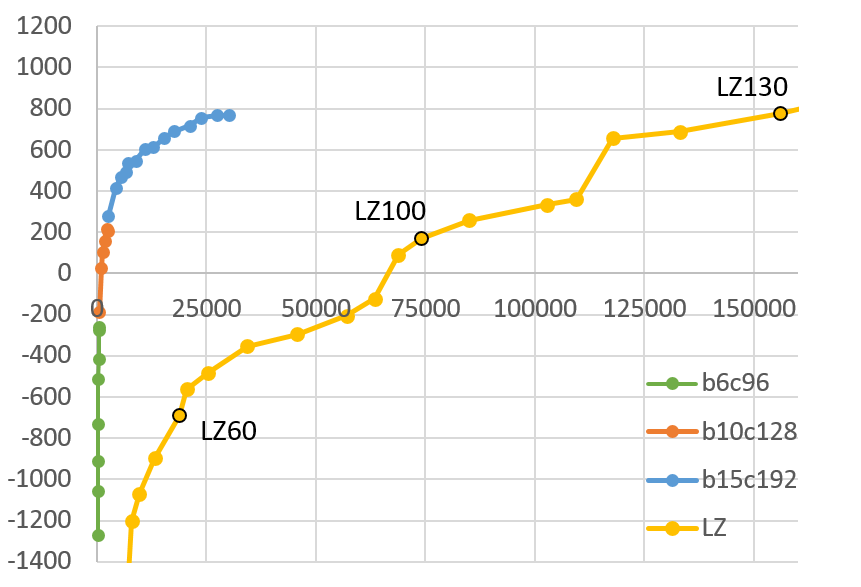
With the help of Jane Street, I’ve now been able to perform a variety of short runs and a medium-length run to begin testing some of these ideas and techniques, some of which might also have further applications beyond just Go. While our runs were not nearly as long as any of the full runs mentioned above, we still achieved strong professional or possibly superhuman levels of strength, along with other interesting and promising results. Today, we’ve released a paper detailing these results.
- Paper: Accelerating Self-Play Learning in Go
- Source code and trained nets: https://github.com/lightvector/KataGo
- Live bot for play online: kata-bot (OGS)
See the paper for more details, but some points of interest:
- Although we have not yet been able to test further, for reaching at least a strong human professional level to a very rough estimate these new techniques togther appear to accelerate learning by as much as a factor of 5 compared to Leela Zero.
- For some earlier parts of training, the improvement was almost a factor of 100. With the code linked above, going from zero up to moderate expert level (amateur-dan level) on the full 19x19 board should now be possible for anyone with merely a few GPUs in as little as a day or two!
- With a minor cost in strength, with the right training architecture a single neural net can be trained to play well on a wide range of board sizes simultaneously.
- Adding score maximization as a secondary objective accelerates learning, at least up to the point we were able to test so far. It also allows the bot to play reasonably in handicap games even without any other special methods, something known to be difficult for other “zero-trained” bots. Example game 1, Example game 2, Example game 3.

Along the way, I also encountered many interesting technical details or directions for further exploration. In the coming months, I hope to run some more experiments and present some of these other ideas and results in future blog posts.



