


It’s the end of another dev internship season, and this one marked something of a transition, since halfway through the season, NY-based interns were invited back to the recently reinvigorated office. Which means that many more of us got the chance to meet and hang out with the interns in person than we did last year. And hopefully the interns were able to get a better sense of Jane Street and how it operates.
Remote or not, the internship is bigger than ever. We had 87 dev interns between New York, London, and Hong Kong from 37 different schools and 21 different countries. As usual, there are way too many interesting projects to describe them all. So I’ve picked just three projects to describe in more depth. In particular:
- Jose Rodriguez extended the functionality of a neat new syntax
extension called
ppx_typed_fields. - Erin Vuong built tools to make it easier for people to dig into historical information about the processes running on their boxes.
- Ohad Rau worked on improving and using a new-ish library called Datafetcher, which helps you write easily testable data processing jobs.
It’s worth saying that this year was an especially hard choice. Here are just some of the projects I considered but chose not to write about:
- A visualizer for Intel’s processor trace tech
- implementing graph-node fusion in an internal graph-computation system
- implementing a distributed sorting algorithm on top of that same system
- building a new meta-PPX to make it way easier to build new syntax extensions
- providing better abstractions for specifying trading limits
And the list goes on.
Anyway, let’s look at the three projects we’re actually going to discuss in more detail. Remember that each one of these just represents half of what one intern got done this summer!
Typed Fields
Jose worked with the Tools and Compilers team on adding functionality
to a fairly new syntax extension called ppx_typed_fields.
First, a bit of background: a syntax extension is basically a way of adding certain types of language features by writing code that transforms the syntax of your program, auto-generating new code for you to use. Jane Street uses a lot of syntax extensions to automate the generation of boring and repetitive code: things like comparison functions, hash functions, serializers and deserializers, and so on.
ppx_typed_fields provides some extra functionality around working
with records. When you define a new record, OCaml by default provides
you with a few basic tools. So if you write:
type t = { foo: int; bar: string }
you now have syntax for constructing the record, for pattern matching on it, and for accessing fields individually.
# let r = { foo = 3; bar = "tomato" }
val r : t = {foo = 3; bar = "tomato"}
# r.foo
- : int = 3
# let { foo; bar } = r in sprintf "%d %s" foo bar
- : string = "3 tomato"
That’s nice enough, but it’s missing something useful: a first-class piece of data that represents a field. Such a value would let you do the ordinary things you might do with a record field, like update the field, extract its value, or compute the field’s name. But because they’re first class, you can use them in a much more general context: you can pass them to a function, serialize them to disk, build custom iterators over them, etc.
Ppx_typed_fields fills this gap. Here’s what we’d write to redefine
our type, but this time, deriving the Typed_fields.
type t = { foo: int; bar: string } [@@deriving typed_fields]
This generates some first class values that can be used for doing things like reading values out of records, or doing a functional update to a record.
# Typed_field.Foo
- : int Typed_field.t = Typed_field.Foo
# Typed_field.get Foo { foo = 5; bar = "banana" }
- : int = 5
# Typed_field.set Bar { foo = 5; bar = "banana" } "asparagus"
- : t = {foo = 5; bar = "asparagus"}
One neat thing you can do is write field validators, and you can use the fact that Typed_field knows the name of the field to generate a useful error message. Here’s the validator:
let validate_field (type a)
field (module M : Identifiable with type t = a) (lo,hi) record =
let v = Typed_field.get field record in
if M.(v <= hi && v >= lo) then Ok ()
else Error (sprintf "Field %s out of bounds: %s is not in [%s,%s]"
(Typed_field.name field) (M.to_string v)
(M.to_string lo) (M.to_string hi))
And here’s how you’d use it:
# let r = { foo = 3; bar = "potato" }
val r : t = {foo = 3; bar = "potato"}
# validate_field Foo (module Int) (5, 10) r;
- : (unit, string) result =
Error "Field foo out of bounds: 3 is not in [5,10]"
# validate_field Bar (module String) ("apple", "banana") r;
- : (unit, string) result =
Error "Field bar out of bounds: potato is not in [apple,banana]"
And that just scratches the surface of what you can do with typed fields.
All of this was in place by the time Jose started. But there were some key missing features:
- Typed fields didn’t work on all kinds of records, in particular, records with type parameters.
- Jose added a new variant on the PPX that handles records inside of records, creating values that let you reference values multiple levels deep in a nested data structure.
That’s all that was initially planned for the project, but Jose
finished up quickly enough that he had time for more, so he went ahead
and added a typed-variants extension which does the analogous thing
for variant types.
The project itself was technically pretty challenging. First of all, typed fields are an example of GADTs (Generalized Algebraic Data Types), which are an advanced feature of the language that takes a bit of time to learn. In addition, Jose had to come to grips with Ppxlib, and had to generalize his code to cover a bunch of tricky special cases in OCaml’s menagerie of type definitions.
ppx_typed_fields is already pretty successful internally, having
been picked up by a half-dozen different projects, and Jose’s
extensions make it more widely applicable. It’s also already
available as part of our open source
release.
Historical atop
Erin Vuong’s project was all about observability. One of the tools we use for gathering data on our systems is atop, which is a system-monitoring tool that computes a lot of useful statistics, and gives you a way of logging them. The great thing about atop versus various other observability tools we have is that it gives you detailed, process-by-process information about your system.
We log data from atop every ten seconds for every production box on our network, and we retain the last 30 days of logs in a central location. But our tooling around using this data is a little limited. You can use the native atop user interface for rewinding to a given date and time and seeing the state of atop at that moment. We’d also built a web-service that lets you get at the same data, but it’s also pretty limited, and in particular, only lets you browse data for a single day. And if you wanted to do something else, well, there’s always awk and sed…
That’s where Erin’s project came in. Her job was to surface time-series data of the behavior of a particular system or process, and to be able to pull that data up across different days. The end result was simple enough: the data just gets uploaded to a spreadsheet for users to slice and dice and analyze to their heart’s content. And the new functionality needed to be surfaced through two different user-interfaces: the command line tools and the web-ui.
Here’s what the web-ui looks like. There’s not much there, and that’s kind of the point! The goal was to make it really simple for users.
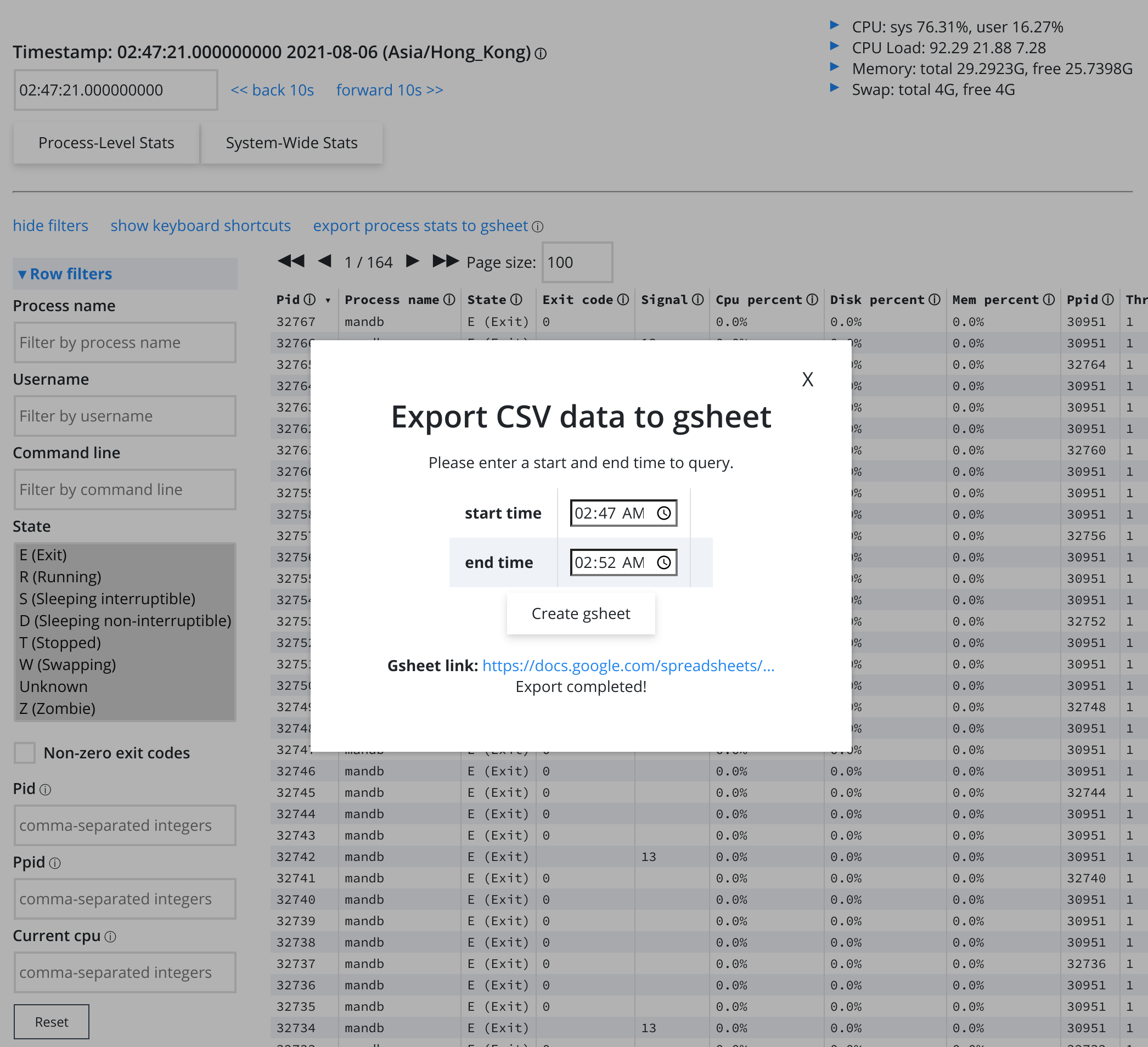
Indeed, part of the challenge here was in designing the various UIs to be easy to use for novice users, while remaining powerful enough for advanced users to get just the data they wanted. So, for example, Erin developed a filtering library that allowed filtering over a familiar regular expression, as well as a complex nested boolean expression. She also developed separate basic and expert commands, so users wouldn’t be exposed to the extra complexity unless they needed it.
Here’s what the basic interface looks like:
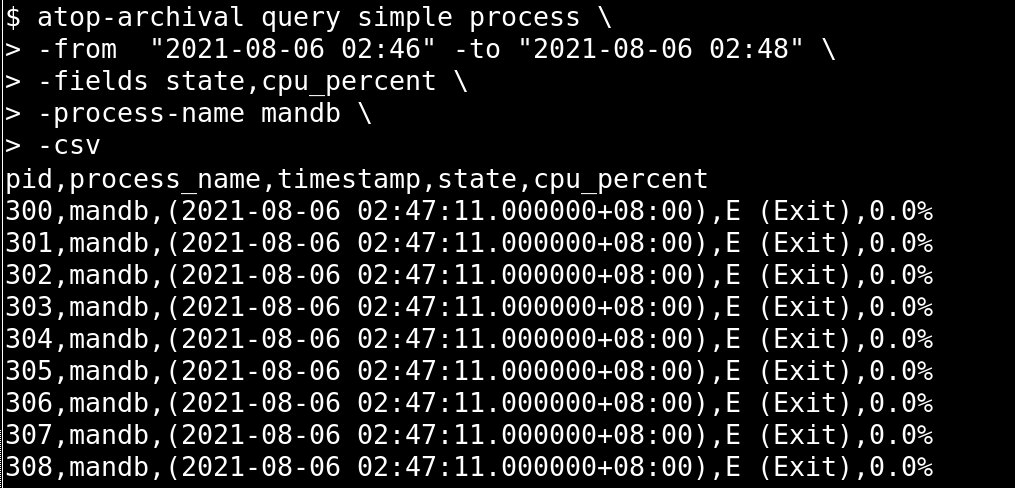
And here’s one using a boolean expression:
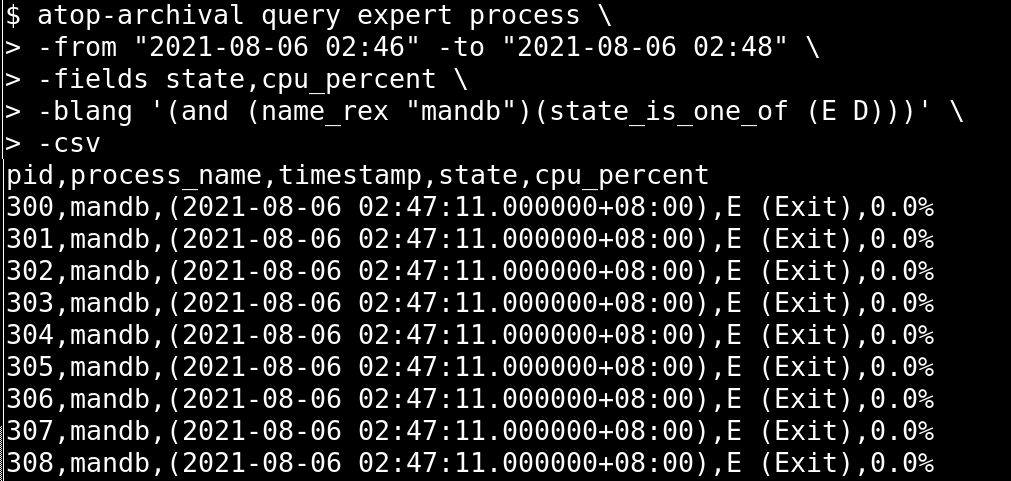
The other challenge of this project was just discovering and resolving a bunch of complex edge cases: making sure we didn’t break our spreadsheet by uploading too much data to it, making sure to do the work incrementally, so you wouldn’t redownload atop data you already had, etc.
Memoization in Datafetcher
One of the things that trading desks need to do is to download various kinds of input data from a variety of sources in order to put together their trading data for the day. This can be surprisingly tricky and time consuming, and it’s frustratingly hard to test. That’s because the work you do depends on a lot of external sources of data, and to test it effectively, you need access to all that data.
Datafetcher is a system that was developed on one of our trading desks for making this kind of thing easier. It’s loosely modeled on Facebook’s Haxl, and it provides you with a little language embedded in OCaml for expressing data-fetching-and-processing jobs. The leaf-nodes in the computation are some kind of “fetch”, an instruction for grabbing external data; and interior nodes in the computation can transform the data, and even guide what data you want to fetch farther down the pipeline.
Here’s what a simple datafetcher program for computing the net-asset-value (NAV) of an ETF might look like.
let get_price component ~date =
let open Datafetcher.Let_syntax in
match%bind Product_type.of_symbol component with
| Equity -> Equity_prices.get_closing_price component ~date
| Future -> Future_prices.get_settlement_price component ~date
let get_nav fund ~date =
let open Datafetcher.Let_syntax in
let%bind currency = Fx.get_currency fund
and component_values =
let%bind { basket; _ } = Composition.load_latest fund ~on_or_before:date in
Datafetcher.List.map (Map.to_alist basket) ~f:(fun (component, weight) ->
let%map price = get_price component ~date in
Money.scale weight price)
in
Fx.add_in_given_currency component_values ~currency
The key win of Datafetcher is that it makes testing massively easier. Because of how Datafetcher is structured, it can be run in multiple modes:
-
In production mode, fetches do the “real” work, kicking off whatever sequence of network requests is required to grab the data in question.
-
In test mode, jobs just read a version of the data that has been previously stored on disk.
-
In record mode, it essentially runs a production job, but records the data you get for use in tests.
The end result is that testing your Datafetcher jobs is incredibly cheap.
That’s not all Datafetcher does for you. It can also batch requests together, which makes your data requests more efficient. And it can cache requests, so if the same data is asked for multiple times in the same job, it only needs to be fetched once.
But there’s a missing bit of functionality in Datafetcher, and that’s where Ohad Rau’s intern project came in. While Datafetcher can cache external fetches, it didn’t cache computations built on top of those fetches. Which means that if your job runs the same computation over and over, then that’s going to be really inefficient.
This was discovered in the course of the desk migrating existing jobs over to Datafetcher, and Ohad’s job was to fix this caching problem. This was tricky, because it required Ohad to mint an identifier for each subcomputation, so you could effectively detect that the computation had already been done in this run.
The end result was that instead of just caching computations at the leaves, Datafetcher now can memoize computations at any intermediate expression.
Ohad finished up the memoization work in the first couple of weeks of his internship, and then turned to converting an existing desk app to use Datafetcher, and when he was done with that, writing a style guide for Datafetcher to give traders who are using the system a sense of what reasonable best practices are.
Sound like fun?
As usual, my hope here is to give you a sense of the kinds of things you might do here if you were an intern. And really, there are way more interesting, challenging, fun projects here than I had a chance to talk about.
So, if it sounds like something you’d be interested in, apply! The internship program is a really great opportunity to learn a lot both about software and about the world of trading. And you can learn more about our interview process here.



