

It’s been an unusual internship season.
Like many companies, Jane Street is operating in distributed mode, and that goes for the internship as well. That meant doing a bunch of things differently, including rethinking how we got the interns up to speed and assigned them to projects and teams.
One change we made was to how interns are assigned to projects. In an ordinary year, interns do two separate projects in totally different parts of the tech organization: a single intern might work on an LDAP implementation for the first half of the summer, and on tools for caching snapshots from exchange-sourced marketdata for the second half.
While we think that kind of diverse experience has its upsides, we didn’t feel like we could do it justice this year, mostly because of time constraints. So this year we assigned each intern to a single team for the whole summer.
That meant that there were fewer projects per intern, but there are still way too many projects to discuss all of them! So, as usual, I picked a few to go into more detail on:
- Henry Nelson’s project to build a Wireshark plugin for Async-RPC, a common internal messaging format. Along the way, Henry built a general purpose library for building Wireshark plugins in OCaml.
- Yulan Zhang’s project to build an application to automatically shard trading systems to better balance the resources they needed and thereby improve performance.
- Eric Martin’s project to help migrate us off an old-and-deprecated regular expression library, leveraging some fancy testing.
Now let’s talk about each project in a bit more detail.
An Async-RPC dissector for Wireshark
Wireshark is an interactive tool for inspecting and viewing network traffic dumps, and it’s an incredibly useful debugging and analysis tool. One of its lovely features is that it understands over 2,500 network protocols out of the box.
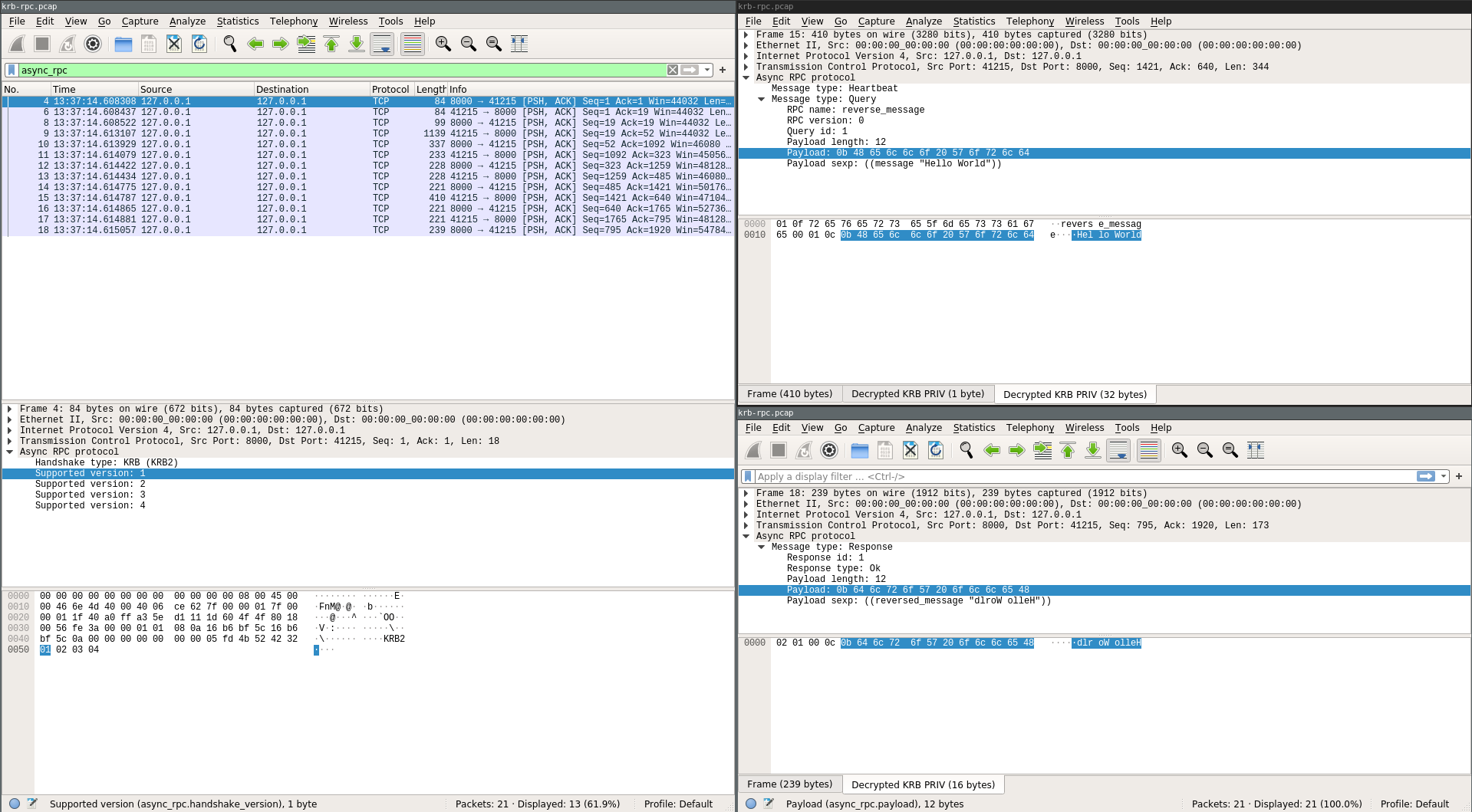
Of course, that doesn’t mean it understands our internal-only protocols. But that’s OK! Wireshark has a plugin interface for adding support for arbitrary network protocols. Henry’s project this summer was to write a plugin for Async-RPC, which is an internally developed protocol that we use all over the place.
In order to support Async-RPC, there are a bunch of different bits and
pieces you need to handle. First of all you need to write code that
knows how to parse Async-RPC’s core Heartbeat, Query, and
Response messages. You also need to be able to deal with messages
that are broken up over multiple packets, and even do data-dependent
packet reassembly. And you need to handle decryption, since we use
Kerberos for some of our message flows.
All of this could be done by just writing more-or-less directly against Wireshark’s standard imperative C API. But that didn’t seem like a great idea, since that API is tricky and hard to reason about. Also, by writing directly against the C API, you end up with a parser that you can’t reasonably test without invoking all of the Wireshark functionality.
Instead, Henry wrote an interface that lets you write your packet
parsing logic in a way that’s abstracted from the concrete details of
interacting with Wireshark, and wraps up the potentially multi-stage
parsing process in what’s called a monadic interface. The details of
monads aren’t important, but the key thing is that we get to use the
special let%bind syntax to mark where we’re giving control back to
Wireshark to go grab more information.
Here’s an example from the Async-RPC dissector of how this API works.
(* Parses a Message.t from lib/async_rpc_kernel/src/protocol.ml *)
let parse_message query_ids tree fields =
let open Parse.Let_syntax in
let open Fields.Rpc in
let%bind message_type, subtree = Wireshark_tree.add_item tree fields.message_type in
match message_type with
| Heartbeat -> return query_ids
| Query -> parse_query query_ids subtree fields
| Response -> parse_response query_ids subtree fields
The Wireshark_tree.add_item call has the effect of both adding a
message type UI element to the Wireshark GUI and returning the message
type so that it can be matched on to determine how to proceed with
parsing. fields.message_type is a special field type that contains
the brains for parsing and displaying the protocol message type.
Packet reassembly is super easy to use. You call
Parse.reassemble_packets_until to tell Wireshark how many bytes of
data you are expecting should be remaining in this logical message.
let parse_priv_encrypted_bigstring ~parse_length_header ~session_key =
let open Parse.Let_syntax in
let%bind length = parse_length_header () in
let%bind () = Parse.reassemble_packets_until ~length in
let%bind data = Parse.parse_out (Field.Reader.of_length ~length) in
Decrypt.decrypt_krb_priv ~session_key data |> Parse.of_or_error
If the data is truncated because the packet has been split, the library will handle reassembling packets from that connection until that much data is available for you and then it will call back into your parsing code as if the data were there all along.
This code also supports seamlessly decrypting and displaying Kerberized RPC packet dumps. The plugin will connect to our internal authorization database and fetch the necessary data for decryption, provided the user in question has the right permissions.
We’re excited about this project both because it gives us an immediate practical tool in the form of Async-RPC support for Wireshark, but also because it gives us a powerful library that makes it simple and easy to build new dissectors for new protocols!
Better sharding through simulated annealing
A lot our trading systems are structured in a pretty similar way: each instance of the trading system is responsible for some number of products, and each of those products implies a bunch of data that you need to consume in order to price and trade that product.
ETFs are an easy-to-understand example of this. An ETF (short for Exchange Traded Fund) is essentially a company whose purpose is to hold a basket of shares of other companies. So, if you buy a share of SPY, you’re effectively buying a small slice of every company in the S&P 500 index.
In order to price an ETF, you want access to the marketdata of the constituents of that ETF; so, in the case of SPY, you’d want to have access to the price of the 500 constituents of the S&P 500 index.
But, each constituent that you want data for demands some resources from the instance consuming it, and therein lies an optimization problem. How do you decide how to spread out ETFs across a collection of instances in such a way as to avoid over-taxing any individual instance? It’s not as easy as it might seem, because the right choice depends not just on the total amount of data you need, but which stocks you need data for, since it’s more efficient to put two ETFs that share many of the same constituents on the same instance.
Our baseline approach to this had been pretty primitive. We used a bunch of embarrassingly manual heuristics and effectively did the sharding by hand. That’s bad for a few reasons: it takes a bunch of time, the by-hand sharding is likely not optimal, and that sharding is not going to get updated as the world changes. How busy you should expect a given security to be changes over time, and the composition of ETFs changes over time as well. If you don’t update your splits from time to time, you’re going to end up leaving performance wins on the ground. And doing the whole thing manually doesn’t incentivize you to do it often.
Yulan ended up working with both the trading desk that was running this process, as well as the research group, which pointed her at some cleaner cost functions to optimize, as well as encouraging her to try out simulated annealing in addition to the greedy algorithm she started with.
And the results look really promising! We now have a solver that you can tell what ETFs to shard and some related metadata, and a few minutes later it spits out a sharding that can be used to drive the configuration of the trading systems. The results look maybe 10%-20% more efficient than the previous by-hand sharding, and, even better, this saves the desk a bunch of frustrating manual work.
Replacing Re2 with Re
An important part of managing technical debt is migrations, i.e., organized projects for removing deprecated code and patterns. Eric Martin’s project was part of just such a migration, in particular, migrating from one regular expression library, Google’s Re2 library, to another one, a pure OCaml library called Re. (As an amusing side-note, our wrapper of Re2 was also an intern project, many years ago!)
We’ve wanted to get rid of Re2 for a while, but it’s tricky.
Replacing it is painful in part because the semantics of Re2 regular
expressions don’t quite line up with the semantics of regular
expressions in Re. Eric’s project was to create a new library,
Re_replace_re2, which is meant to be a drop-in replacement for our
Re2 wrappers, which we could automatically smash into place across
the tree.
How hard could it be? Well, the answer, it turns out, is pretty hard. The first task was to get a parser which could be used to produce an an abstract syntax tree (AST) representing the structure of the regular expression.
Instead of writing a parser in OCaml, Eric’s instead hooked into the
existing Re2 parser, and used that to produce an OCaml data
structure representing the AST. This has a few advantages:
- It’s easier than reverse engineering
Re2to write a parser from scratch. - Even though it doesn’t entirely drop our dependency on
Re2, it does reduce the amount of code we depend on. - Down the line, we hope to use it to mechanically convert
Re2-style patterns to patterns thatRealready knows how to parse, letting us further reduce our reliance on Re2. - Finally, assuming we do eventually need to write a pure OCaml parser, having a nice wrapped-up version of the C++ parser makes testing it easier.
But parsing isn’t the only job that needs to be done. Once you have
the AST to represent the Re2 regexp, you still need some way to encode
it in Re. And that’s tricky, because, despite them both being
“regular expression” engines, they don’t quite implement classical
regular expressions; they always have a few, often ill-specified,
extensions up their sleeve, which makes the translation a bit more
fraught.
So a big part of the story of getting this library right was testing!
Eric deployed
Quickcheck for
doing some
bisimulation-style
testing to check that Re_replaces_re2 behaves the same way as Re2
proper. (Quickcheck is a neat idiom for building probability
distributions for generating examples for tests, and bisimulation is a
technique where you essentially run two implementations of the same
program together and check the results against each other.)
Eric also used a seemingly magical tool called AFL, which is a fuzzer that is shockingly good at generating test cases to exercise specially instrumented programs. He used this specifically for finding bugs in his C++ parsing code.
Anyway, the end result of all this good work is that we have a version
of Re_replace_re2 that’s nearly ready to be used, at least to remove
a large fraction of the uses of Re2. There are still some semantic
gaps (some of which depend on fixes to Re itself that Eric
submitted upstream!),
which means it’s not quite ready to replace Re2 everywhere. All of
which goes to show, migrations are hard work.
Sound like fun? Then apply!
I hope this gives you a feel for the kind of work interns get to do at Jane Street. We aim to give interns projects that both teach them interesting things, and also have real impact on the organization. I think we did pretty well on that this summer.
If this sounds like fun to you, you should apply. And this is a good place to start if you want to learn more about the interview process.
(Links to Reddit and HN, if you want to comment on the post.)



