

This blog post is about an interesting detail about machine learning that I came across as a researcher at Jane Street - that of the interaction between L2 regularization, also known as weight decay, and batch normalization.
In particular, when used together with batch normalization in a convolutional neural net with typical architectures, an L2 objective penalty no longer has its original regularizing effect. Instead it becomes essentially equivalent to an adaptive adjustment of the learning rate!
This and similar interactions are already part of the awareness in the wider ML literature, for example in Laarhoven or Hoffer et al.. But from my experience at conferences and talking to other researchers, I’ve found it to be surprisingly easy to forget or overlook, particularly considering how commonly both batch norm and weight decay are used.
For this blog post, we’ll assume that model fitting is done via stochastic gradient descent. With ADAM or other alternative optimizers, the analysis presented here does not necessarily apply (particularly as the notions of weight decay versus an L2 objective penalty now become nonequivalent, as explored by Loshchilov and Hutter), and the behavior will be potentially different.
L2 Regularization / Weight Decay
To recap, L2 regularization is a technique where the sum of squared parameters, or weights, of a model (multiplied by some coefficient) is added into the loss function as a penalty term to be minimized.
Let be the collection of model weights, and be any mini-batch, and be the learning rate, and be the current error we are minimizing with respect to the data. With L2 regularization our overall loss function will be of the form:
During gradient descent, our update step will look like:
So the effect of the L2 penalty term is that on each optimization step in addition to stepping based on a gradient to better fit the training data, all model weights also decay proportionally towards zero by a small factor of . This is why this technique is also known as “weight decay”.
Purpose/Intuition
Usually, the motivation for L2 regularization is to reduce overfitting.
One way to intuit this is that weight decay will continuously squeeze model weights to be too small, increasing error on the training data. However, important weights that capture common regularities in the data will consistently recover back up on future steps, re-reducing that error. Weight values that are merely due to noise in a particular batch or to only small numbers of data samples and that do not affect the error much will not recover so readily. In this way, the final model weights (hopefully) fit the more of the broader regularities in the data and less of the noise. This is how an L2 penalty regularizes the model.
Alternatively, a Bayesian view would be that the penalty imposes a prior about the “complexity” of the model. In function approximation, models that precisely wiggle to fit every data point in a noisy setting tend to require very large weights to generate the necessary sharp kinks to do so and are less likely to generalize. Models with smaller weights will generally be smoother and more likely to generalize. By directly penalizing large weights, we favor smoother and less “complex” models.
Batch Normalization
Batch normalization is a technique where layers are inserted into typically a convolutional neural net that normalize the mean and scale of the per-channel activations of the previous layer. Depending on the architecture, this is usually somewhere between each nonlinear activation function and prior convolutional layers (He et al.).
Let be the output tensor of a batch norm layer, and be the output tensor of the layer that feeds into it. As before, let be the model weights of the previous (linear) layer. Then we have:
where:
and is a typically negligible constant that ensures no division by zero. For notation we use here to denote indices into the relevant vectors and tensors, and we also have as an argument everywhere to emphasize that we are considering everything as a function of , as will be useful below.
So for each channel , will be the same as except shifted and rescaled to have mean zero and standard deviation one. Typically one or two learnable parameters are further added, but we omit those for simplicity as they do not affect the analysis in this post.
Purpose/Intuition
Batch normalization was introduced by a 2015 paper (Ioffe and Szegedy), with the idea of stabilizing the distribution of layer activations over the course of training, reducing the instability of deeper neural nets to saturate or diverge. But exactly why it helps appears to still be a topic of research (for example, see Santurkar et al. or Bjorck et al.).
Empirically for convolutional neural nets on some (but not all) problems, batch normalization stabilizes and accelerates the training while reducing the need to tune a variety of other hyperparameters to achieve reasonable performance.
The key property that is relevant for this post is that batch norm layers make the neural net output approximately invariant to the scale of the activations of the previous layers. Any such scaling will simply be normalized away, except for the tiny effect of the in the denominator.
What Happens When Both Are Used Together
What happens when both batch norm and an L2 objective penalty are used together in a convolutional neural net? To first order, the weight decay from the L2 penalty on a convolutional layer no longer has an influence on the output of the neural net!
With a little thought, this should not be surprising. Since batch norm makes the output invariant to the scale of previous activations, and the scale of previous activations is linearly related to the scale of the model weights, the output will now be invariant to weight decay’s scaling of those weights.
Formally, let be the model weights for a convolutional layer, let be the output tensor for that layer. Assume that the feeds into a batch norm layer, and let be the output of that batch norm layer, viewed as a function of .
Suppose that as a result of an L2 penalty term or direct weight decay, we scale by a factor .
Since convolution is a linear operation, scaling the weight matrix of a convolution simply scales the output. Also straightforwardly from their earlier definitions, and also scale linearly with . Therefore:
Then the new output of the batch norm layer is:
So a scaling by approximately has no effect on the output, as expected. Note also that this property does not depend on the batch size. (except perhaps if the noise in extremely tiny batch sizes makes it slightly more common for a layer to be tiny and to matter).
No More L2 Regularization Mechanism
What happens when we try to use an L2 objective penalty term with batch normalization present?
Since the neural net’s output is invariant to the scale of , the mechanism by which the weight decay would normally regularize the neural net is broken!
Without batch norm, important weights should experience gradients to restore their magnitudes countering earlier weight decays, whereas weights fitting only noise would on average remain decayed. But with batch norm, all weights will be “equally happy” at the decayed value as at the original value. Since it is a proportional decay, the batch norm layer will automatically “undo” the decay and there will be no gradient to preferentially increase the magnitude of the important entries within relative to the less important ones.
Or more formally, it’s pretty easy to show that if a given function is invariant to multiplicative scalings of , then the direction of the gradient must also be invariant to multiplicative scalings of . In other words, weight decay’s scaling of the weights cannot directly alter the direction of future gradient descent steps to favor any components of over any others (although it could alter the size of the overall steps).
The Bayesian perspective is another way to intuit why there should be no regularization effect now. An L2 penalty term normally acts as a prior favoring models with lower “complexity” by favoring models with smaller weights. But when the model is invariant to the scale of the weights, an L2 penalty no longer accomplishes this. With batch norm, models with smaller weights are no more or less “complex” than ones with larger weights, since rescaling the weights of a model produces an essentially equivalent model.
New Effect on Gradient Scale and Learning Rate
Does that mean L2 regularization is pointless with batch norm present? No - actually it takes on a major new role in controlling the effective learning rate of the model during training. Here’s how:
Without batch norm, the weights of a well-behaving neural net usually don’t grow arbitrarily, since an arbitrary scaling of all the weights will almost certainly worsen the data loss. In my experience, it’s pretty common for weights to remain near same order of magnitude that they were initialized at.
But with batch norm, they are unconstrained since an increase in the overall magnitude of the weights in any layer will simply result in the subsequent batch norm layer scaling all the activations down again. So the weights can grow significantly over time, and absent any controlling force in practice they very much do. As we will see, this has a major effect on the magnitude of the gradients.
Effect of Scale on Gradients
Consider as before what happens when we scale the model weights of a convolutional layer by a factor , when there is a subsequent batch norm layer. What happens to the gradient of the loss function on the data with respect to ?
Intuitively, the gradients should vary inversely with . For example, if a given absolute step changes the loss by some amount , then doubling all the weights means that after batch norm cuts in half all the activations, the same absolute-sized step will only have half as large an effect on the activations, so should be halved.
Mathematically, this translates to the following (non-rigorous) derivation. Heuristically using several times the fact that for any reasonable-scale , and letting be any particular entry within :
(it’s possible to be more rigorous about the above and about how much affects the quality of the approximation , but for simplicity we avoid doing so here).
So as expected, scaling by a factor of causes the gradients to scale by a factor of . Additionally, since with batch norm what matters is the scale of gradient steps relative to the existing magnitude of , and itself is still times larger, this effectively scales the learning rate of by a factor of .
Consequences for Learning Rate
With batch norm removing any inherent constraint on the scale of , absent any other constraint, we would expect to naturally to grow in magnitude over time through stochastic gradient descent. This is because a random walk’s distance from the origin grows in magnitude over time with very high probability (this is true even when batch normalization causes every gradient step in parameter space to have no locally inward or outward component, since we are taking finite-sized steps and a finite-sized step tangent to the surface of a sphere will end up slightly further outside of that sphere).
Then by the scaling of the gradient, this will in effect cause the learning rate to greatly decay over time. As grows, the relative step sizes will shrink quadratically.
So without an L2 penalty or other constraint on weight scale, introducing batch norm will introduce a large decay in the effective learning rate over time. But an L2 penalty counters this.
With an L2 penalty term to provide weight decay, the scale of will be bounded. If it grows too large, the multiplicative decay will easily overwhelm any outward motion due to random walking. In the limit of training for a very long time at a fixed nominal learning rate, one would expect that the scale of would tend toward an equilibrium level where the expansion due to random walking average precisely balanced out the weight decay. This prevents the gradient and therefore the effective learning rate from decaying over time.
Summary
So to a first-order approximation, once you are using batch normalization in a neural net, an L2 objective penalty term or weight decay no longer contribute in any direct manner to the regularization of layers that precede a batch norm layer. Instead, they take on a new role as the unique control that prevents the effective learning rate from decaying over time.
This could of course itself result in better regularization of the final neural net, as maintaining a higher learning rate for longer might result in a broader and better-generalizing optimium. But this would be a result of the dynamics of the higher effective learning rate, rather than the L2 objective penalty directly penalizing worse models.
Of course, this analysis does not hold for any layers in a neural net that occur after all batch normalization layers, for example typically the final fully-connected layers in common architectures. In those layers, obviously the normal regularization mechanism applies. Other variations on architecture might also affect this analysis. And as mentioned near the start of this post, if you are using an optimizer other than stochastic gradient descent (or stochastic gradient decent with momentum - the analysis is very similar), things might also be a little different.
Experiment
As a demonstration of the above, in theory we should be able to closely replicate the effect of an L2 objective penalty in a batch-normalizing neural net purely by adjusting the learning rate in the various layers to perform the same learning-rate scaling that the weight decay would have resulted in. And we can do exactly that!
Using TensorFlow version 1.11 we train the ResNet-20 model (version 1, no preactivation) on CIFAR-10 based on code from the official TensorFlow model examples repo. Conveniently, the official example model provided already uses both batch normalization and an L2 objective penalty (with a hardcoded coefficient of 0.0002).
As a baseline, we train for 50 epochs with a learning rate of 0.1, then 50 epochs with 0.01, then 50 epochs with 0.001, leaving other hyperparameters untouched from defaults. Additionally, we train a second model where we remove all convolutional layers from the L2 objective penalty (but not the final layers of the neural net, since all convolutional layers are followed by a batch normalization layer but the final “head” layers are not).
Here is a plot of the test set prediction accuracy of the resulting models over the course of training:
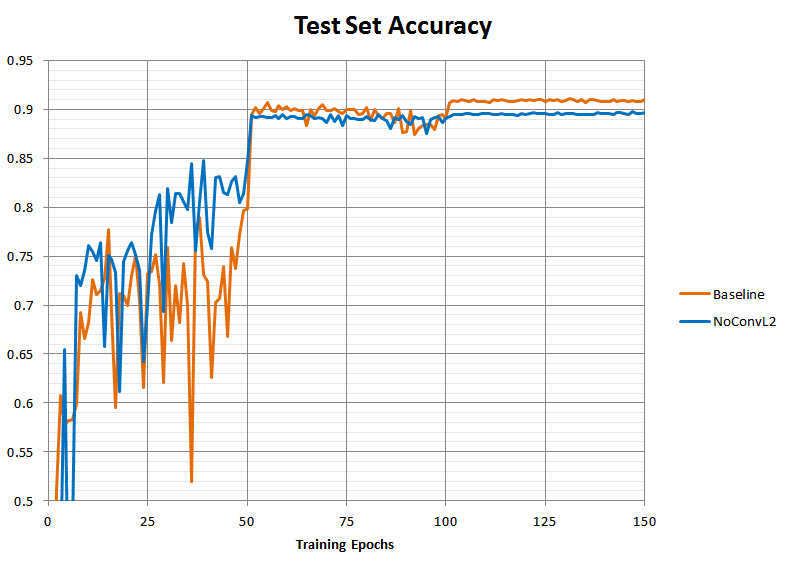
The model without the L2 penalty (“NoConvL2”) ended up worse than the baseline, stabilizing around 89.5% rather than 91% accuracy. If the theory is correct that L2 in the presence of batch norm functions as a learning-rate scaling rather than a direct regularizer, then this worsened accuracy should be due to something that resmbles a too-quick learning rate drop rather than a similar-to-baseline training curve with merely somewhat worse overfitting. Without the L2 penalty to keep the scale of the weights contained, they should grow too large over time, causing the gradient to decay, effectively acting as a too-rapid learning rate decrease.
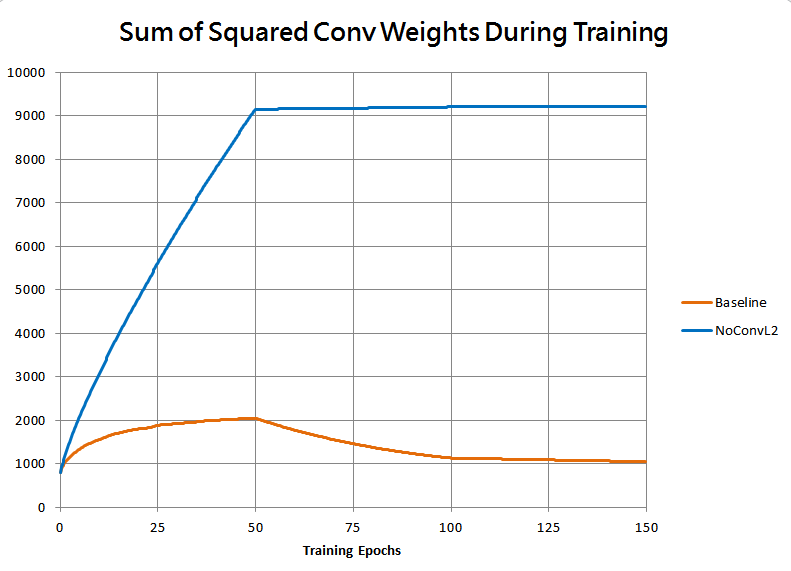
This is borne out by the following plot of the sum of squared weights in all convolutional layers for the two runs:
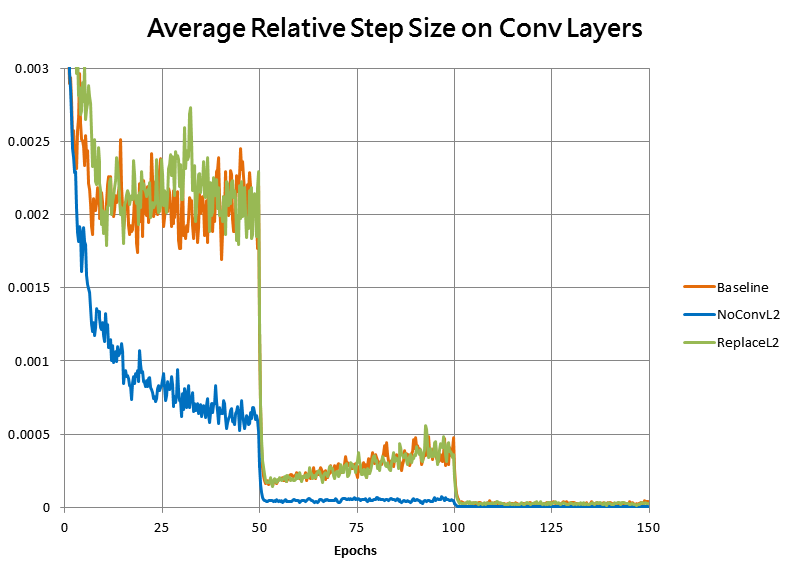
As well as by the magnitude of the average optimizer step on convolutional layers, divided by the norms of the weights for those layers:
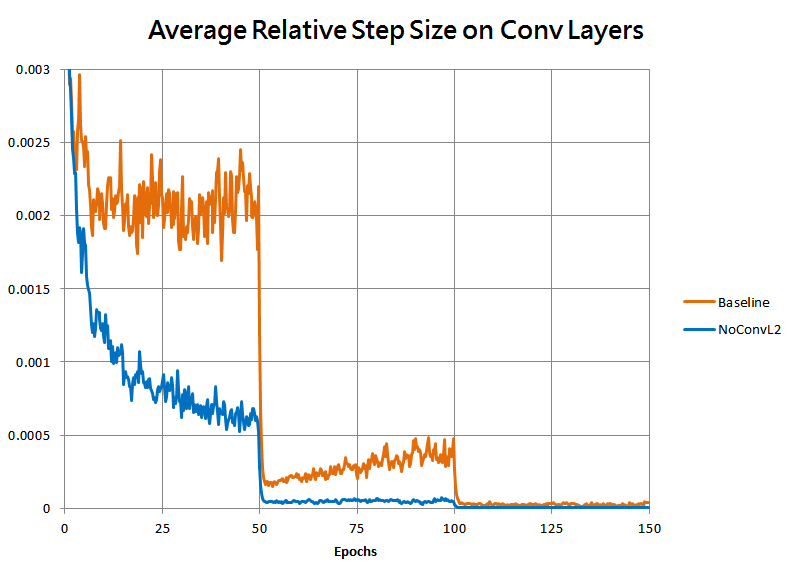
As expected, without the L2 penalty the weights grew much faster, causing the relative step size to decay, dropping the speed of learning far too fast for the model to reach as good of a fit.
(As an interesting note, it turns out that at least in these runs, the worse fit arguably manifests both as more underfitting and more overfitting! Drilling down reveals the NoConvL2 run had about an 0.024 logit or 7% larger final difference between training and test losses, suggesting worse overfitting, but the training loss itself was about 0.025 logits worse as well, suggesting some underfitting too.)
Now for the fun part: theoretically, we should be able to restore the original training behavior without adding back the L2 penalty, by manually adjusting the learning rate for the convolutional layers to increase over time at precisely the right rate to counteract the weight growth and reproduce the learning rate of the baseline.
And since with batch norm there should be no meaningful direct regularization effect from the L2 penalty that we will need to reproduce, theoretically we will not need to add any additional regularization to achieve the baseline accuracy again.
Let’s try this. Since the effective step size on the convolutional layers would diminish over time inversely with the squared magnitude of the weights, we compute the squared magnitude of the weights and scale the gradients to compensate. A crude snippet of TensorFlow code in Python to do this looks roughly like:
conv2d_sqsum = tf.add_n([
tf.reduce_sum(tf.square(tf.cast(v, tf.float32))) for v in tf.trainable_variables()
if ("conv2d" in v.name)
])
initial_conv2d_sqsum = 800.0 # empirical initial value of conv2d_sqsum for Resnet-20
# We will multiply gradients by this:
conv_lr_factor = conv2d_sqsum / initial_conv2d_sqsum
Additionally, the average squared magnitude of the convolutional weights in the baseline run itself was not constant! So to replicate the baseline training, we also need to multiply the gradients by the inverse of that as well. We observe what this actually was in our baseline run, and then crudely approximate it with a piecewise linear function for the purposes of implementing it in TensorFlow, which is plotted below:
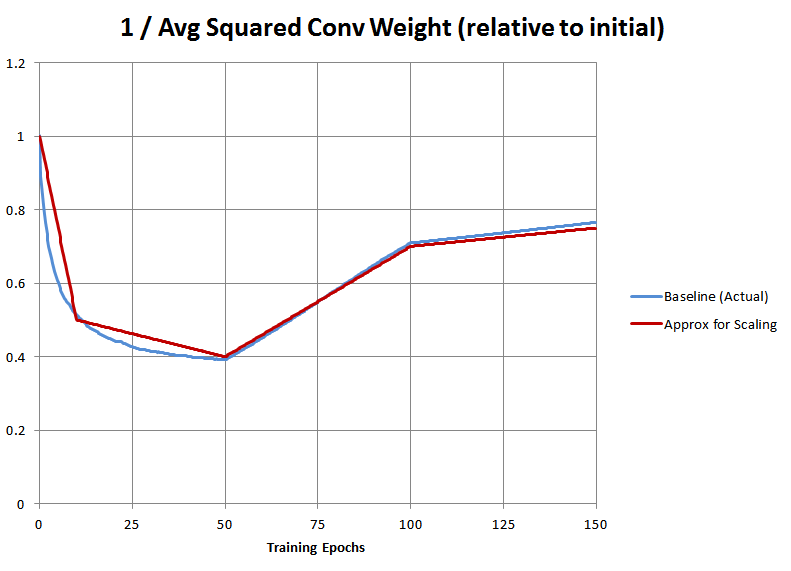
Giving us this final hacky bit of code that we insert into the TensorFlow example code:
conv2d_sqsum = tf.add_n([
tf.reduce_sum(tf.square(tf.cast(v, tf.float32))) for v in tf.trainable_variables()
if ("conv2d" in v.name)
])
initial_conv2d_sqsum = 800.0 # empirical initial value of conv2d_sqsum for Resnet-20
...
conv_lr_factor = tf.where(epoch < 10.0, (1.0 - 0.05 * epoch),
tf.where(epoch < 50.0, (0.5 - 0.0025 * (epoch-10.0)),
tf.where(epoch < 100.0,(0.4 + 0.006 * (epoch-50.0)),
(0.7 + 0.001 * (epoch-100.0)))))
conv_lr_factor *= conv2d_sqsum / initial_conv2d_sqsum
grad_vars = optimizer.compute_gradients(loss)
scaled_grad_vars = []
for (g,v) in grad_vars:
if "conv2d" in v.name:
scaled_grad_vars.append((conv_lr_factor*g, v))
else:
scaled_grad_vars.append((g,v))
grad_vars = scaled_grad_vars
...
Here’s the resulting run attempting to replace the L2 objective term with this equivalent scaling:
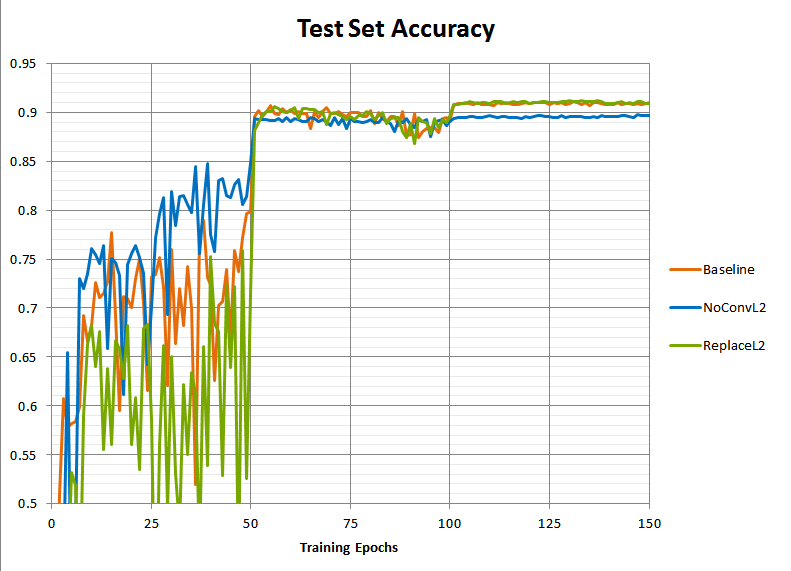
Not bad! The new run does have the same final accuracy as the baseline. However the accuracy during the first learning rate regime is now a lot worse on average. Why is that?
This turns out to be because although we’ve closely replicated the training, at inference time the batch normalization layers use a moving average of statistics from training. During the first learning rate regime, our replicated training has model weights growing exponentially over time instead of maintaining a similar magnitude throughout because rather than using an L2 penalty to bound their scale, we’re simply adjusting the learning rate to be even larger to keep up. So the training modulo the scale of the weights is the same, but at inference time the batch norm moving averages will always be too small, as they can’t keep up with the exponential growth.
If we wanted, we could simply shrink the window for the moving averages a little to help them keep up, (by changing the hardcoded “_BATCH_NORM_DECAY” constant in the TensorFlow example from 0.997 to 0.98). This has absolutely no effect on the training, but should improve the inference-time accuracy within the first learning rate regime:
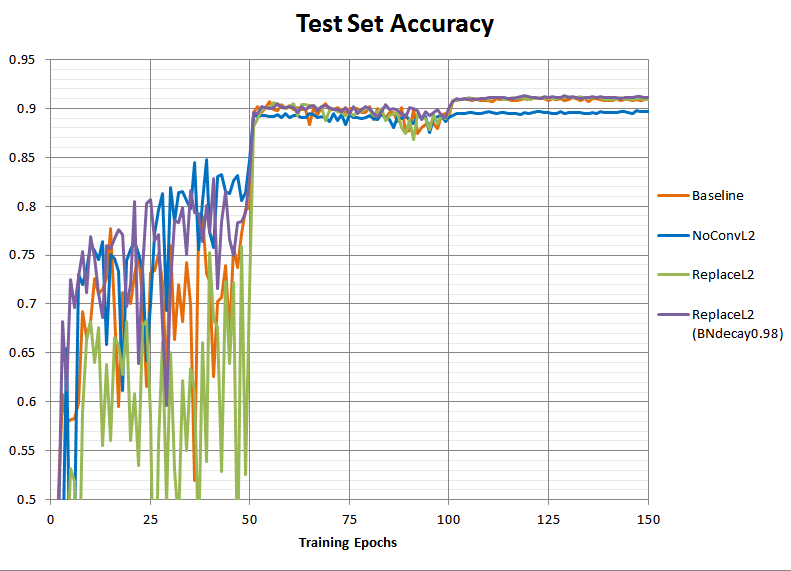
And indeed it does. In fact, it looks like we’ve overshot slightly - presumably in the baseline run the batch norm moving averages were already having difficulty keeping up due to the high learning rate alone, so with a shorter moving average window our purple test accuracy line is actually a little higher than the baseline orange in the first 50 epochs.
Here’s a plot of the average relative step size for the first three training runs together again, which shows that indeed our manual learning rate scaling has indeed replicated the step-size behavior of the original training:
And here’s a plot of the magnitude of the convolutional weights for those runs, this time on a log scale:
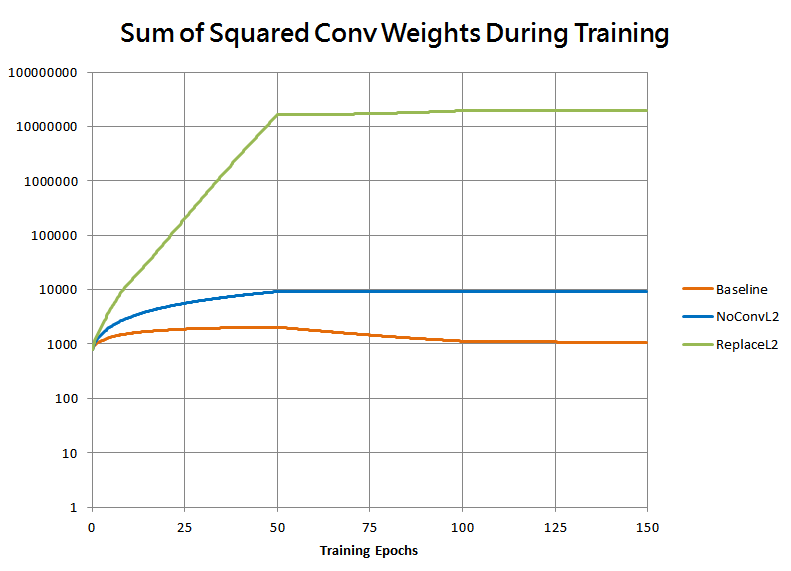
As expected, the weights grow exponentially to some quite extreme values, far larger than baseline! This shows that the cumulative effect of weight decay over time on a batch-normalizing neural net, when viewed instead as a learning rate adjustment, can be massive.
In summary, an L2 penalty or weight decay on any layers preceding batch normalization layers, rather than functioning as a direct regularizer preventing overfitting of the layer weights, instead takes on a role as the sole control on the weight scale of that layer. This prevents the gradients and therefore the “effective” learning rate for that layer from decaying over time, making weight decay essentially equivalent to a form of adaptive learning rate scaling for those layers.



